
From Data Mining to Data Minding
- Deep Knowledge Group

- Oct 23, 2018
- 5 min read
Updated: May 11, 2023
Deep Knowledge Group Discovers Key Data Science Principles to Outperform Large LLMs at Financial and Investment Information Extraction

Introducing Text Mining
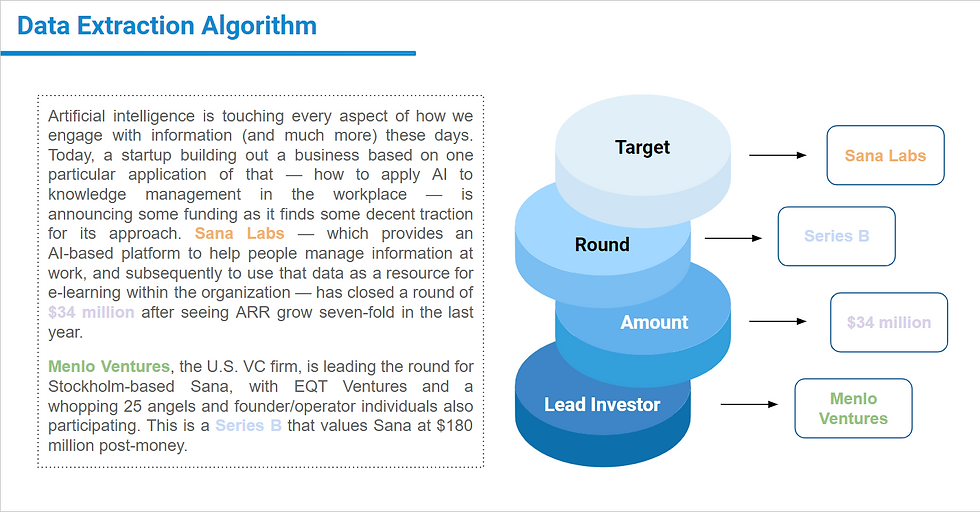
AI algorithms are revolutionizing the financial industry through a process known as “text mining” - the quick and accurate analysis of large bodies of text for the purposes of investment decision making.
Advanced algorithms can now read through vast numbers of financial reports and effortlessly extract key points, generating investment recommendations and even triggering trading actions.
Furthermore, these technologies are used to monitor and analyze press releases, industry events, and other relevant media sources, allowing industry players to better understand market trends and make more informed decisions at a faster pace.
“Coupled with big data analytics, the field of text mining is evolving continuously. Finance is one major sector that can benefit from these techniques; the analysis of large volumes of financial data is both a need and an advantage for corporations, government, and the general public.” - Gupta et al., 2020
However, current approaches have proved cumbersome and inefficient and are desperately in need of an upgrade.
Given the highly competitive nature of the financial industry, speed and quality are critical for success, and many industry players are striving to excel in this field building fast and efficient models.
Classical text interpretation involves several key tasks, including:
Sentiment analysis which identifies and extracts emotions or opinions expressed in a piece of text, such as a social media post, a review, or a news article.
Text classification which categorizes a piece of text into one or more predefined categories; for example, classifying emails as spam or not spam, and categorizing news articles into topics such as sports, politics, or entertainment, or in the case of finance, finance-related subtopics.
Information extraction that automatically extracts structured information from unstructured or semi-structured data sources, such as text documents, web pages, or social media posts. It involves identifying and extracting relevant pieces of information, such as names, dates, locations, and events, and organizing them in a structured format, such as a database or a spreadsheet.
While high-quality algorithms exist for the first two tasks, there is still a lack of proper products in the market for the third.
What’s so hard about information extraction?
Typically, the information extraction task is divided into two separate tasks: Named Entity Recognition (NER) and Relation Extraction (RE).
Named entity recognition (NER) is the task of identifying and classifying named entities in text, such as people, organizations, and locations. Relation extraction (RE) is the task of identifying relationships between named entities called subject and object in text, e.g., the relationship between the organization and group of investors during the funding round described in the news article, relation between participants of M&A event, supply chain connections etc.
The process of combing through vast amounts of data for recognizable names and named entities is nothing short of a herculean task that demands both significant computational resources and human effort. With datasets often comprising millions of documents, each potentially containing dozens or even hundreds of named entities, this task requires a great deal of computational time and effort.
Despite the challenges, the benefits of text mining are too great to ignore, making it a critical tool in the financial industry and beyond for gaining invaluable insights into complex data sets. As such, organizations continue to invest heavily in this technology to uncover hidden patterns, detect risks, and capitalize on emerging opportunities.
The Latest in State-of-the-art Data Extraction
The AI industry on the other hand offers new models and tools that are able to address the demand of financial companies. Accuracy of those models is crucial to guarantee high-quality signal generation and avoid making trading decisions based on erroneous outcomes.
In particular, a recent breakthrough in large language models (LLMs) offers a universal solution to both extraction tasks.
Bloomberg have documented their solution of what amounts to the largest and most accurate finance-specific LLM, outlined in their 2020 treatise on “BloombergGPT”:
“We achieve strong results on general LLM benchmarks and outperform comparable models on financial tasks. We attribute this, in decreasing order of impact, to 1) a well-curated internal dataset, 2) our unique choice in tokenizer, and 3) an up-to-date architecture.” - Wu et al., 2023
And as recently as March 2023, Morgan Stanley detailed their use of GPT-4 in a partnership with OpenAI:
“Starting last year, the company began exploring how to harness its intellectual capital with GPT’s embeddings and retrieval capabilities—first GPT-3 and now GPT-4. The model will power an internal-facing chatbot that performs a comprehensive search of wealth management content and “effectively unlocks the cumulative knowledge of Morgan Stanley Wealth Management,” says Jeff McMillan, Head of Analytics, Data & Innovation, whose team is leading the initiative. GPT-4, his project lead notes, has finally put the ability to parse all that insight into a far more usable and actionable format.
“You essentially have the knowledge of the most knowledgeable person in Wealth Management—instantly”, McMillan adds. “Think of it as having our Chief Investment Strategist, Chief Global Economist, Global Equities Strategist, and every other analyst around the globe on call for every advisor, every day. We believe that is a transformative capability for our company.”
Morgan Stanley conducts experiments similar to Bloomberg by fine-tuning GPT-4 model on its proprietary corpus of texts.
The universal nature of the LLMs makes them attractive alternatives to the task-specific models. But how good are they really?
These state of the art models have shown impressive performance in various natural language processing tasks, information extraction tasks included.
The success of these models often depends on the quality and size of the training data, the fine-tuning strategy, the quality of prompts, and the evaluation metrics used.
The performance of these models can be significantly improved by fine-tuning them on a mixture of tasks, especially when the tasks have some underlying similarity or share common features.
This raises the question: what if we were able to use smaller models?
The Hidden Efficiency of Smaller Models
We investigated this question and found that longer training on smaller models leads to better performance. Taking into account the computing budget, the largest models are not the best choice, especially for RE mentioned previously.
While smaller models require more computational resources for training, this pays off in the long run. We have researched the optimal model size and training methodology to achieve the best performance on information extraction tasks to retrieve information about funding rounds from news sources.
We have examined the data requirements in terms of dataset size and diversity of tasks on the performance of specific information-extraction tasks, and we have discovered that we simply don’t need extra large datasets for every single task, instead, the best performance is achieved when we have diverse datasets!
Deep Knowledge Group Keeping it Lean and Mean
We have now utilized this insight to create a custom, proprietary, smaller, better trained LLM that outperforms the larger models mentioned above for the task of financial and investment data analysis and information extraction.
Our experiments show that it’s efficient to use models smaller than 1 billion parameters for information extraction. For this, we don’t require the model to have extended factual knowledge, but rather a more efficient grasp of the key patterns therein, and relations between key concepts. It doesn’t need to know everything, just understand what it needs to know.
This will become clearer as the model develops and the solution reveals itself!
In fact, we performed better with relatively small models than with larger ones such as GPT4. Since we used a relatively small dataset, adapting small models can be the most efficient approach.
We look forward to sharing further insights with you as these innovations progress.


I discovered Grow A Garden recently and instantly became hooked on the relaxing gameplay and charming garden design. Planting crops and creating beautiful spaces makes the game very enjoyable. It’s one of the most entertaining free online farming games I have played!